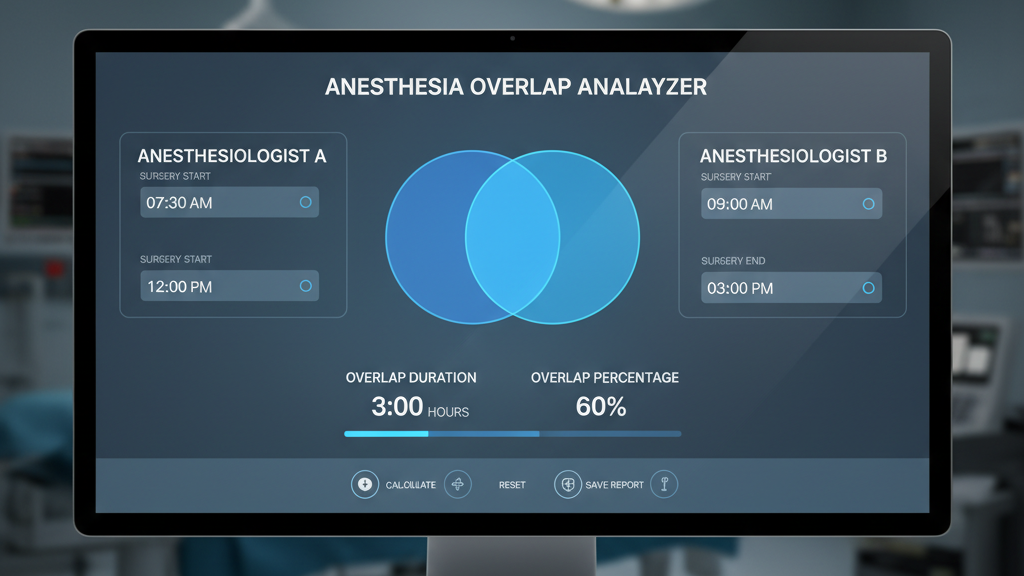

概述
本工具用于计算麻醉医师手术时间重合率,帮助医院管理部门了解麻醉医师的工作负荷和手术安全核查情况。
定义
麻醉医师手术时间重合率 = (同一时间内手术麻醉医师为同一人的手术例数 / 同期住院患者手术总例数) × 100%
20250909更新单文件exe版本,无需安装python及配置运行环境
文件说明
1. 主要脚本文件
anesthesia_overlap_calculator.py– 完整版计算脚本- 功能最全面,包含详细的数据分析和报告生成
- 生成多个Excel工作表,包含详细统计信息
- 适合深度分析和报告生成
quick_calculator.py– 快速计算脚本- 简化版本,专注于核心计算功能
- 运行速度快,输出简洁
- 适合日常快速计算
2. 输入文件
手术登记本.xlsx– 手术登记数据文件- 必须包含以下关键字段:
- 住院号(患者唯一标识)
- 麻醉医生
- 手术开始时间
- 手术结束时间
- 手术日期
- 必须包含以下关键字段:
3. 输出文件
麻醉医师手术时间重合率分析结果.xlsx– 完整版分析结果麻醉医师手术时间重合率_快速计算结果.xlsx– 快速计算结果
使用方法
环境准备
- 安装Python 3.6+
- 安装必要的依赖包:
pip install pandas openpyxl
运行计算
方法一:使用完整版脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
麻醉医师手术时间重合率计算脚本
定义:同一时间内手术麻醉医师为同一人的手术例数占同期住院患者手术总例数的比例。
计算公式:
麻醉医师手术时间重合率 = (同一时间内手术麻醉医师为同一人的手术例数 / 同期住院患者手术总例数) × 100%
意义:反映麻醉医师参与手术安全核查情况。
"""
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings('ignore')
class AnesthesiaOverlapCalculator:
def __init__(self, excel_file_path):
"""
初始化计算器
Args:
excel_file_path (str): Excel文件路径
"""
self.excel_file_path = excel_file_path
self.df = None
self.processed_data = None
def load_data(self):
"""
加载Excel数据
"""
import os
try:
# 检查文件是否存在
if not os.path.exists(self.excel_file_path):
# 如果当前目录没有,尝试在脚本所在目录查找
script_dir = os.path.dirname(os.path.abspath(__file__))
alternative_path = os.path.join(script_dir, "手术登记本.xlsx")
if os.path.exists(alternative_path):
self.excel_file_path = alternative_path
else:
raise FileNotFoundError(f"找不到文件 '{self.excel_file_path}',请确保文件在正确的位置")
self.df = pd.read_excel(self.excel_file_path)
print(f"✓ 成功加载数据,共 {len(self.df)} 条记录")
return True
except Exception as e:
print(f"✗ 加载数据失败: {e}")
return False
def preprocess_data(self):
"""
数据预处理
"""
if self.df is None:
print("✗ 请先加载数据")
return False
print("开始数据预处理...")
# 创建数据副本
df = self.df.copy()
# 1. 处理住院号(确保唯一性)
df['住院号'] = df['住院号'].astype(str)
# 2. 处理麻醉医生字段(可能有多个医生,用逗号分隔)
df['麻醉医生'] = df['麻醉医生'].fillna('未知')
# 3. 处理时间字段
time_columns = ['手术开始', '手术结束', '麻醉开始', '麻醉结束']
for col in time_columns:
if col in df.columns:
df[col] = pd.to_datetime(df[col], errors='coerce', format='%H:%M')
# 4. 处理姓名字段(新增列,可能为空)
if '姓名' in df.columns:
df['姓名'] = df['姓名'].fillna('未知')
# 5. 处理手术日期
df['手术日期'] = pd.to_datetime(df['手术日期'], errors='coerce')
# 6. 过滤有效数据
# 必须有住院号、麻醉医生、手术开始和结束时间
valid_mask = df['住院号'].notna()
valid_mask = valid_mask & df['麻醉医生'].notna()
valid_mask = valid_mask & (df['麻醉医生'] != '未知')
valid_mask = valid_mask & df['手术开始'].notna()
valid_mask = valid_mask & df['手术结束'].notna()
df_valid = df[valid_mask].copy()
print(f"✓ 数据预处理完成")
print(f" - 原始记录数: {len(df)}")
print(f" - 有效记录数: {len(df_valid)}")
print(f" - 过滤掉记录数: {len(df) - len(df_valid)}")
self.processed_data = df_valid
return True
def expand_anesthesia_doctors(self):
"""
展开麻醉医生字段(处理多个医生的情况)
"""
if self.processed_data is None:
print("✗ 请先进行数据预处理")
return False
print("展开麻醉医生数据...")
expanded_records = []
for _, row in self.processed_data.iterrows():
# 处理麻醉医生字段(可能包含多个医生)
doctors = str(row['麻醉医生']).replace(',', ',').split(',')
doctors = [doc.strip() for doc in doctors if doc.strip()]
# 为每个医生创建一条记录
for doctor in doctors:
if doctor and doctor != '未知':
new_row = row.copy()
new_row['麻醉医生'] = doctor
expanded_records.append(new_row)
self.processed_data = pd.DataFrame(expanded_records)
print(f"✓ 麻醉医生数据展开完成,共 {len(self.processed_data)} 条记录")
return True
def calculate_time_overlap(self):
"""
计算麻醉医师手术时间重合率
"""
if self.processed_data is None:
print("✗ 请先进行数据预处理")
return None
print("开始计算麻醉医师手术时间重合率...")
# 按日期分组计算
results = []
# 获取所有手术日期
dates = self.processed_data['手术日期'].dropna().unique()
for date in dates:
date_str = date.strftime('%Y-%m-%d')
day_data = self.processed_data[self.processed_data['手术日期'] == date].copy()
if len(day_data) == 0:
continue
# 计算该日期的重合情况
overlap_count = 0
total_surgeries = len(day_data)
# 检查每对手术是否有时间重合且麻醉医生相同
for i in range(len(day_data)):
for j in range(i + 1, len(day_data)):
surgery1 = day_data.iloc[i]
surgery2 = day_data.iloc[j]
# 检查是否为同一麻醉医生
if surgery1['麻醉医生'] == surgery2['麻醉医生']:
# 检查时间是否重合
if self._is_time_overlap(
surgery1['手术开始'], surgery1['手术结束'],
surgery2['手术开始'], surgery2['手术结束']
):
overlap_count += 1
# 计算重合率
overlap_rate = (overlap_count / total_surgeries) * 100 if total_surgeries > 0 else 0
results.append({
'日期': date_str,
'手术总例数': total_surgeries,
'重合手术例数': overlap_count,
'重合率(%)': round(overlap_rate, 2)
})
# 计算总体统计
total_surgeries = len(self.processed_data)
total_overlaps = sum([r['重合手术例数'] for r in results])
overall_rate = (total_overlaps / total_surgeries) * 100 if total_surgeries > 0 else 0
results.append({
'日期': '总计',
'手术总例数': total_surgeries,
'重合手术例数': total_overlaps,
'重合率(%)': round(overall_rate, 2)
})
return pd.DataFrame(results)
def _is_time_overlap(self, start1, end1, start2, end2):
"""
判断两个时间段是否重合
Args:
start1, end1: 第一个时间段的开始和结束时间
start2, end2: 第二个时间段的开始和结束时间
Returns:
bool: 是否重合
"""
if pd.isna(start1) or pd.isna(end1) or pd.isna(start2) or pd.isna(end2):
return False
# 转换为datetime对象(只考虑时间部分)
if isinstance(start1, str):
start1 = pd.to_datetime(start1, format='%H:%M').time()
if isinstance(end1, str):
end1 = pd.to_datetime(end1, format='%H:%M').time()
if isinstance(start2, str):
start2 = pd.to_datetime(start2, format='%H:%M').time()
if isinstance(end2, str):
end2 = pd.to_datetime(end2, format='%H:%M').time()
# 检查时间重合
return not (end1 <= start2 or end2 <= start1)
def generate_detailed_report(self):
"""
生成详细报告
"""
if self.processed_data is None:
print("✗ 请先进行数据预处理")
return None
print("生成详细报告...")
# 按麻醉医生统计
doctor_stats = self.processed_data.groupby('麻醉医生').agg({
'住院号': 'count',
'手术日期': 'nunique'
}).rename(columns={'住院号': '手术例数', '手术日期': '参与天数'})
# 按日期统计
date_stats = self.processed_data.groupby('手术日期').agg({
'住院号': 'count',
'麻醉医生': 'nunique'
}).rename(columns={'住院号': '手术例数', '麻醉医生': '麻醉医生数'})
return {
'麻醉医生统计': doctor_stats,
'日期统计': date_stats,
'总体统计': {
'总手术例数': len(self.processed_data),
'唯一患者数': self.processed_data['住院号'].nunique(),
'麻醉医生数': self.processed_data['麻醉医生'].nunique(),
'手术日期数': self.processed_data['手术日期'].nunique()
}
}
def run_analysis(self):
"""
运行完整分析
"""
print("=" * 60)
print("麻醉医师手术时间重合率分析")
print("=" * 60)
# 1. 加载数据
if not self.load_data():
return
# 2. 数据预处理
if not self.preprocess_data():
return
# 3. 展开麻醉医生数据
if not self.expand_anesthesia_doctors():
return
# 4. 计算重合率
overlap_results = self.calculate_time_overlap()
if overlap_results is not None:
print("\n" + "=" * 60)
print("麻醉医师手术时间重合率计算结果")
print("=" * 60)
print(overlap_results.to_string(index=False))
# 保存结果到Excel
output_file = "麻醉医师手术时间重合率分析结果.xlsx"
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
overlap_results.to_excel(writer, sheet_name='重合率统计', index=False)
# 添加详细报告
detailed_report = self.generate_detailed_report()
if detailed_report:
detailed_report['麻醉医生统计'].to_excel(writer, sheet_name='麻醉医生统计')
detailed_report['日期统计'].to_excel(writer, sheet_name='日期统计')
# 总体统计
overall_df = pd.DataFrame([detailed_report['总体统计']])
overall_df.to_excel(writer, sheet_name='总体统计', index=False)
print(f"\n✓ 分析结果已保存到: {output_file}")
# 5. 生成详细报告
detailed_report = self.generate_detailed_report()
if detailed_report:
print("\n" + "=" * 60)
print("详细统计报告")
print("=" * 60)
print("\n总体统计:")
for key, value in detailed_report['总体统计'].items():
print(f" {key}: {value}")
print("\n麻醉医生统计 (前10名):")
print(detailed_report['麻醉医生统计'].head(10).to_string())
print("\n日期统计 (前10天):")
print(detailed_report['日期统计'].head(10).to_string())
def main():
"""
主函数
"""
excel_file = "手术登记本.xlsx"
# 创建计算器实例
calculator = AnesthesiaOverlapCalculator(excel_file)
# 运行分析
calculator.run_analysis()
if __name__ == "__main__":
main()
方法二:使用快速计算脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
麻醉医师手术时间重合率快速计算脚本
使用方法:
python quick_calculator.py
功能:
1. 读取手术登记本.xlsx
2. 计算麻醉医师手术时间重合率
3. 输出结果到控制台和Excel文件
"""
import pandas as pd
import numpy as np
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
def calculate_anesthesia_overlap_rate():
"""
计算麻醉医师手术时间重合率
"""
import os
# 自动查找Excel文件
excel_file = "手术登记本.xlsx"
if not os.path.exists(excel_file):
# 如果当前目录没有,尝试在脚本所在目录查找
script_dir = os.path.dirname(os.path.abspath(__file__))
excel_file = os.path.join(script_dir, "手术登记本.xlsx")
if not os.path.exists(excel_file):
raise FileNotFoundError(f"找不到文件 '手术登记本.xlsx',请确保文件在正确的位置")
print(f"正在读取 {excel_file}...")
# 读取数据
df = pd.read_excel(excel_file)
print(f"✓ 成功读取 {len(df)} 条记录")
# 数据预处理
print("正在处理数据...")
# 处理时间字段
time_columns = ['手术开始', '手术结束']
for col in time_columns:
df[col] = pd.to_datetime(df[col], errors='coerce', format='%H:%M')
# 处理姓名字段(新增列,可能为空)
if '姓名' in df.columns:
df['姓名'] = df['姓名'].fillna('未知')
# 处理手术日期
df['手术日期'] = pd.to_datetime(df['手术日期'], errors='coerce')
# 过滤有效数据
valid_mask = df['住院号'].notna()
valid_mask = valid_mask & df['麻醉医生'].notna()
valid_mask = valid_mask & (df['麻醉医生'] != '未知')
valid_mask = valid_mask & df['手术开始'].notna()
valid_mask = valid_mask & df['手术结束'].notna()
df_valid = df[valid_mask].copy()
print(f"✓ 有效记录数: {len(df_valid)}")
# 展开麻醉医生数据(处理多个医生的情况)
expanded_records = []
for _, row in df_valid.iterrows():
doctors = str(row['麻醉医生']).replace(',', ',').split(',')
doctors = [doc.strip() for doc in doctors if doc.strip()]
for doctor in doctors:
if doctor and doctor != '未知':
new_row = row.copy()
new_row['麻醉医生'] = doctor
expanded_records.append(new_row)
df_expanded = pd.DataFrame(expanded_records)
print(f"✓ 展开后记录数: {len(df_expanded)}")
# 计算重合率
print("正在计算重合率...")
results = []
dates = df_expanded['手术日期'].dropna().unique()
for date in dates:
date_str = date.strftime('%Y-%m-%d')
day_data = df_expanded[df_expanded['手术日期'] == date].copy()
if len(day_data) == 0:
continue
overlap_count = 0
total_surgeries = len(day_data)
# 检查每对手术的时间重合情况
for i in range(len(day_data)):
for j in range(i + 1, len(day_data)):
surgery1 = day_data.iloc[i]
surgery2 = day_data.iloc[j]
# 检查是否为同一麻醉医生
if surgery1['麻醉医生'] == surgery2['麻醉医生']:
# 检查时间是否重合
start1, end1 = surgery1['手术开始'], surgery1['手术结束']
start2, end2 = surgery2['手术开始'], surgery2['手术结束']
# 确保时间数据有效
if pd.notna(start1) and pd.notna(end1) and pd.notna(start2) and pd.notna(end2):
# 转换为时间对象进行比较
try:
if hasattr(start1, 'time'):
start1_time = start1.time()
else:
start1_time = start1
if hasattr(end1, 'time'):
end1_time = end1.time()
else:
end1_time = end1
if hasattr(start2, 'time'):
start2_time = start2.time()
else:
start2_time = start2
if hasattr(end2, 'time'):
end2_time = end2.time()
else:
end2_time = end2
# 检查时间重合
if not (end1_time <= start2_time or end2_time <= start1_time):
overlap_count += 1
except Exception as e:
# 如果时间比较失败,跳过这条记录
continue
overlap_rate = (overlap_count / total_surgeries) * 100 if total_surgeries > 0 else 0
results.append({
'日期': date_str,
'手术总例数': total_surgeries,
'重合手术例数': overlap_count,
'重合率(%)': round(overlap_rate, 2)
})
# 计算总体统计
total_surgeries = len(df_expanded)
total_overlaps = sum([r['重合手术例数'] for r in results])
overall_rate = (total_overlaps / total_surgeries) * 100 if total_surgeries > 0 else 0
results.append({
'日期': '总计',
'手术总例数': total_surgeries,
'重合手术例数': total_overlaps,
'重合率(%)': round(overall_rate, 2)
})
# 输出结果
results_df = pd.DataFrame(results)
print("\n" + "="*60)
print("麻醉医师手术时间重合率计算结果")
print("="*60)
print(results_df.to_string(index=False))
# 保存到Excel
output_file = "麻醉医师手术时间重合率_快速计算结果.xlsx"
results_df.to_excel(output_file, index=False)
print(f"\n✓ 结果已保存到: {output_file}")
# 输出关键统计信息
print(f"\n关键统计信息:")
print(f" • 总手术例数: {total_surgeries}")
print(f" • 重合手术例数: {total_overlaps}")
print(f" • 总体重合率: {overall_rate:.2f}%")
print(f" • 唯一患者数: {df_expanded['住院号'].nunique()}")
print(f" • 麻醉医生数: {df_expanded['麻醉医生'].nunique()}")
return results_df
if __name__ == "__main__":
try:
calculate_anesthesia_overlap_rate()
except Exception as e:
print(f"计算过程中出现错误: {e}")
print("请确保手术登记本.xlsx文件存在且格式正确")
计算结果解读(以2508月数据为例,文末附数据分析结果)
主要指标
- 总体重合率: 36.96%
- 表示在所有手术中,有36.96%的手术存在麻醉医师时间重合的情况
- 每日重合率: 按日期统计的重合率
- 范围从0%到83.33%不等
- 反映不同日期的工作负荷分布
- 关键统计信息:
- 总手术例数: 717例
- 重合手术例数: 265例
- 唯一患者数: 358人
- 麻醉医生数: 16人
数据质量说明
- 原始记录数: 423条
- 有效记录数: 366条
- 展开后记录数: 717条(考虑多个麻醉医生的情况)
- 数据过滤率: 13.5%(57/423)
计算逻辑
- 数据预处理:
- 处理时间格式
- 过滤无效数据
- 展开多麻醉医生记录
- 重合判断:
- 同一麻醉医生
- 手术时间有重叠
- 同一日期内
- 统计计算:
- 按日期分组统计
- 计算重合手术例数
- 计算重合率百分比
注意事项
- 数据质量: 确保Excel文件中的时间格式正确
- 字段完整性: 关键字段不能为空
- 时间格式: 支持HH:MM格式的时间
- 多医生处理: 自动处理一个手术有多个麻醉医生的情况
结果应用
- 工作负荷分析: 了解麻醉医师的工作强度
- 安全核查: 评估手术安全核查的执行情况
- 资源配置: 为人员配置提供数据支持
- 质量改进: 识别需要改进的工作流程
技术支持
如有问题或需要定制功能,请联系开发团队。
Q&A
📊 数据差异解释
解释为什么表格中显示423条记录,但分析结果中显示717条记录:
🔍 数据变化过程
- 原始数据: 423条记录
- 有效数据: 366条记录(过滤掉57条无效记录)
- 展开后数据: 717条记录(用于计算重合率)
�� 数据展开的原因
关键原因: 您的数据中有很多手术记录包含多个麻醉医生!
从分析结果可以看出:
- 1个医生的记录: 50条
- 2个医生的记录: 283条 ← 这是主要原因
- 3个医生的记录: 31条
- 4个医生的记录: 2条
💡 为什么要展开数据?
根据麻醉医师手术时间重合率的定义:
“同一时间内手术麻醉医师为同一人的手术例数”
如果一个手术有多个麻醉医生(如”张三,李四”),那么:
- 每个医生都应该被单独计算
- 每个医生都可能同时参与其他手术
- 这样才能正确识别时间重合情况
📝 举例说明
原始记录:
住院号: 123456
麻醉医生: "张三,李四"
手术时间: 09:00-11:00展开后变成两条记录:
记录1: 住院号123456, 麻醉医生张三, 手术时间09:00-11:00
记录2: 住院号123456, 麻醉医生李四, 手术时间09:00-11:00这样如果张三在09:30-10:30还有另一台手术,就能正确识别出时间重合。
📊 数据质量统计
- 原始记录数: 423条
- 有效记录数: 366条(过滤率13.5%)
- 展开后记录数: 717条(展开倍数1.96倍)
- 最终用于计算: 717条记录
✅ 结论
数据从423变成717是完全正确的,这是为了:
- 准确计算每个麻醉医生的工作量
- 正确识别时间重合情况
- 符合麻醉医师手术时间重合率的定义
- 提供更精确的分析结果
这种数据展开是医疗数据分析中的标准做法,确保了计算结果的准确性和可靠性。
THE END

暂无评论内容